





"The price of peace is eternal vigilance" - George C. Marshall's maxim, though conceived for statecraft, resonates powerfully in the context of wind turbine maintenance. In managing fleets often comprising dozens of turbines, operational excellence demands unwavering attention, as multiple failure points can emerge at any time. Experience has consistently shown that presuming worst-case scenarios until proven otherwise yields superior operational outcomes.
A Gearbox Failure: Initial Indicators
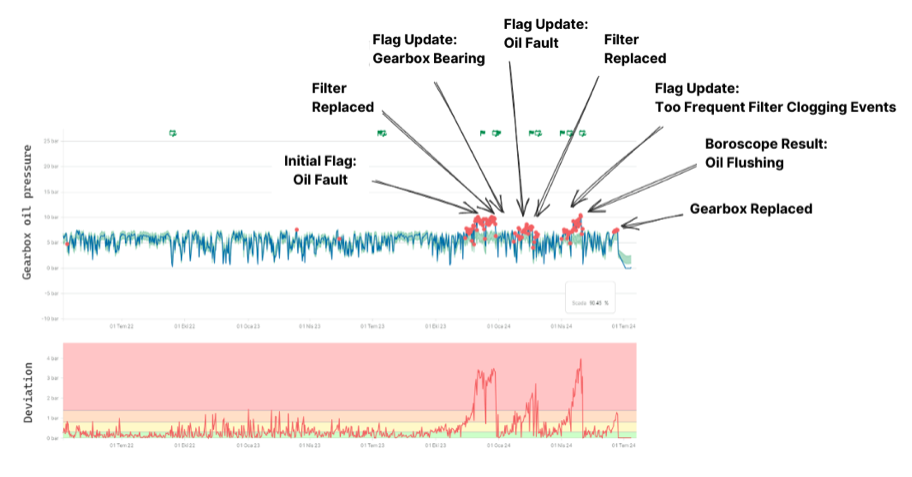
On December 9, 2023, Kavaken's Predictive Maintenance module detected abnormal gearbox oil pressure patterns in a client's 2.5 MW turbine—an early warning that conventional SCADA systems failed to register. This anomaly would prove to be the harbinger of an eventual complete gearbox failure. Significantly, Kavaken's Power Booster module, which monitors power curve performance, simultaneously identified early signs of output degradation—a critical correlation that traditional monitoring systems typically overlook.
Following established protocols, maintenance teams performed an oil filter replacement on December 28. This standard intervention, though routine, would later prove revelatory of a critical flaw in maintenance thinking. The subsequent gearbox failure demonstrated how the tendency to default to common solutions—such as filter replacement for oil pressure anomalies—can become a dangerous operational blind spot. The lesson is clear: in wind turbine maintenance, standard protocols must be accompanied by exceptional vigilance and rigorous analysis to avoid misjudgment due to the bias of assuming simpler, more common issues.
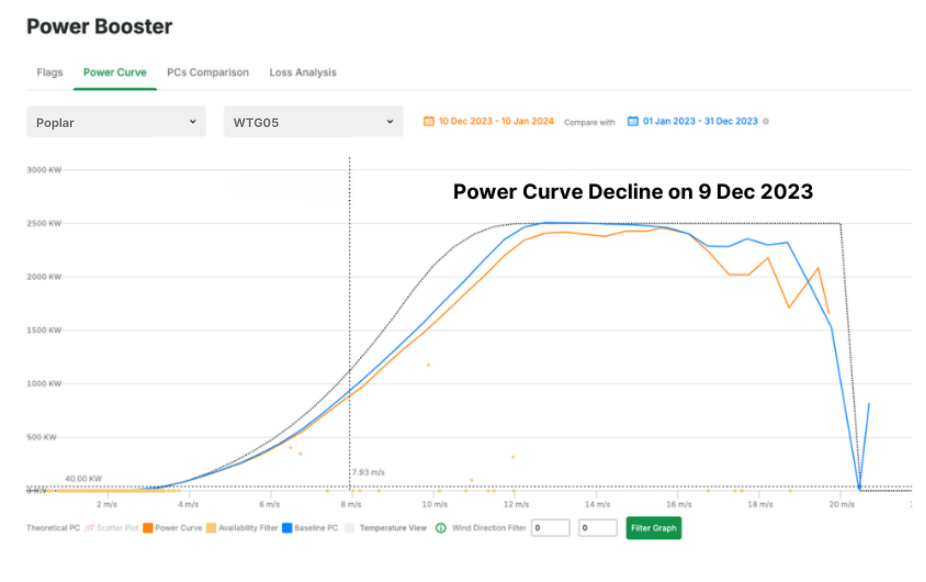
Escalating Signals
By January 1, 2024, Kavaken's system continued to detect persistent anomalies despite the recent maintenance intervention. While oil pressure readings increasingly deviated from normal parameters, traditional SCADA systems—constrained by fixed thresholds—remained silent. By late February, the deviations had intensified, prompting a second filter replacement on February 28. Though this intervention yielded temporary improvements, it exemplified another fundamental maintenance principle: symptomatic relief can obscure underlying pathologies, demanding heightened vigilance precisely when systems appear to recover.
Borescope Inspection
The maintenance challenge evolved into a clear performance issue by spring 2024. Despite conducting a thorough borescope inspection in late April, followed by an oil system flush on May 21, the fundamental problem—progressive wear in transmission elements—continued to elude detection. This phase illuminates a crucial insight: even sophisticated visual inspections, while valuable, may fail to reveal root causes without proper methodological rigor. The human element compounds this challenge, particularly when inspectors lack a solid failure hypothesis to guide their investigation (i.e., where they should look deeper in the whole system)—a common scenario given the multitude of potential failure modes in complex turbine systems.
The Failure
The sequence culminated in catastrophic gearbox failure on June 23, 2024, forcing the turbine's complete shutdown. Post-failure inspection revealed extensive wear and breakage in transmission components between stage gears—damage that had accumulated progressively over months. The subsequent gearbox replacement operation extended to 21 days, prolonged by adverse weather conditions and crane malfunction. The total production losses amounted to 668MWh, including 610MWh from the shutdown period and additional losses from earlier performance degradation.
No Room for Complacency
This case study yields several fundamental insights about wind turbine maintenance systems:
First, the progression from initial warning to system failure demonstrates that advanced analytics alone cannot prevent failures without corresponding evolution in response protocols. A parallel can be drawn with the space industry's "prove-safe" paradigm—where launch decisions default to no-go until safety is affirmatively demonstrated, rather than proceeding unless risks are found. This approach suggests that in wind turbine maintenance, every anomaly, regardless of magnitude, warrants thorough investigation until definitively proven benign.
Second, reliance on any single monitoring system—even sophisticated ones—proves insufficient for comprehensive issue detection. Traditional OEM-provided SCADA systems, with their fixed thresholds, are particularly limited; by the time their alarms trigger, it is invariably too late. Condition Monitoring Systems (CMS), on the other hand, have a limited coverage as vibration sensors feeding these systems usually are only available for main components, leaving the sub-components uncovered. Even advanced methods such as applying machine learning with SCADA data that can cover both main and subcomponents and actually have the ability to identify a problem at a subcomponent that can later affect a main one, while crucial, cannot guarantee complete coverage. The optimal approach requires a sophisticated array of complementary monitoring tools, perhaps including investments in various competitive solutions available in the market, where gaps in one system's detection capabilities are covered by others.
Third, the relationship between mechanical condition and performance degradation reveals a complexity that eludes basic monitoring systems. The significant production losses incurred before complete failure underscore why sophisticated analytical systems require multiple monitoring approaches working in concert—each contributing to a more comprehensive understanding of turbine health.
For wind farm operators, the implications extend far beyond technological considerations. As turbines grow larger and more complex, the industry must embrace a fundamental shift in mindset: from reactive monitoring to proactive verification, from single-system reliance to multiple overlapping approaches, and from threshold-based alerts to prescriptive analytics. Nevertheless, a sobering reality remains: even with these advances in monitoring sophistication, no human-made system is entirely fail-proof—unexpected failures can still occur despite best practices and vigilant oversight. Yet this inherent limitation should not deter the pursuit of excellence; as monitoring systems evolve, each improvement reduces failure probability by a pinch more, making wind energy more profitable. Every advancement contributes to improved production, revenue, and investment returns—the key performance indicators impact renewable energy economics.
.png)




